Namenode is a Hadoop master daemon responsible for managing the file system namespace & regulates clients access. There is only one primary Namenode & one secondary Namenode in a default Hadoop configuration. Namenode runs in the master cluster node. [Hadoop 3.x permits multiple secondary namenode]
The secondary name node is a helper daemon, it reads the Edit Log file generated by the primary namenode and updates the FSImage file, this process is known as Checkpoint, after successful checkpoint the edit log gets truncated. Checkpoint operation is I/O intensive process, therefore the secondary Namenode offloads this activity from the primary Namenode. If and when the primary Namenode is not available the secondary name not doesn’t get promoted to a primary role. It waits for the primary Namenode to comeback and provide the latest FSImage to it.
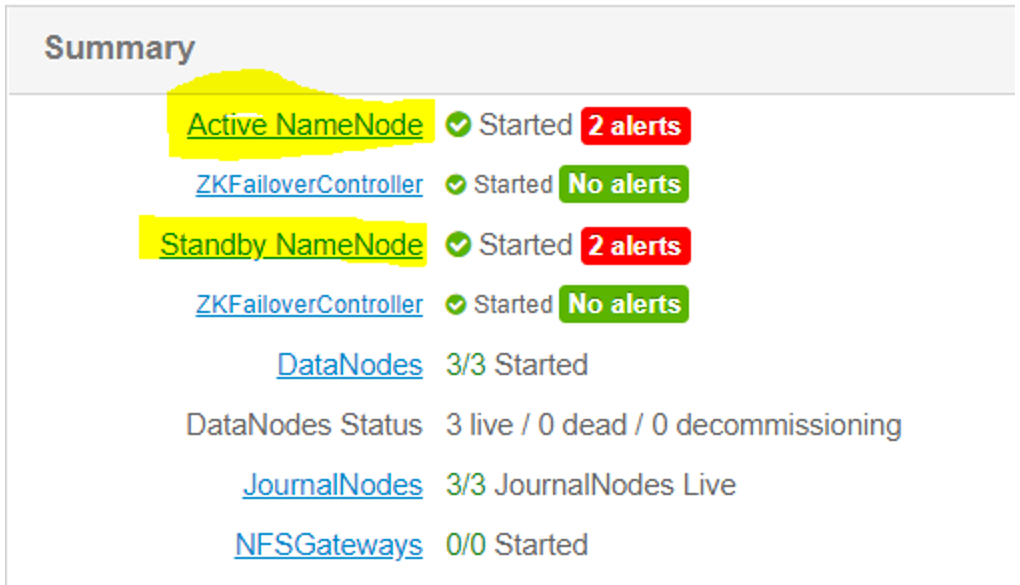
Hadoop provides Namenode high availability (HA) through a standby Namenode daemon. The standby Namenode keeps in synch with the primary Namenode through Journalnode daemons. When the primary Namenode makes any namespace change, it logs the change in a Journalnode, the standby Namenode reads this log file (Edit Log) from the Journalnode.
In the event of active node failover, the standby Namenode will ensure that it has read all of the edit log files from the Journalnode prior to being promoted to a primary Namenode. A Zookeeper Failover Controller (ZKFC) is used to avoid a split brain scenario between Namenodes during failover by expiring a lock of the active Namenode and electing new Namenode which gets granted the lock.
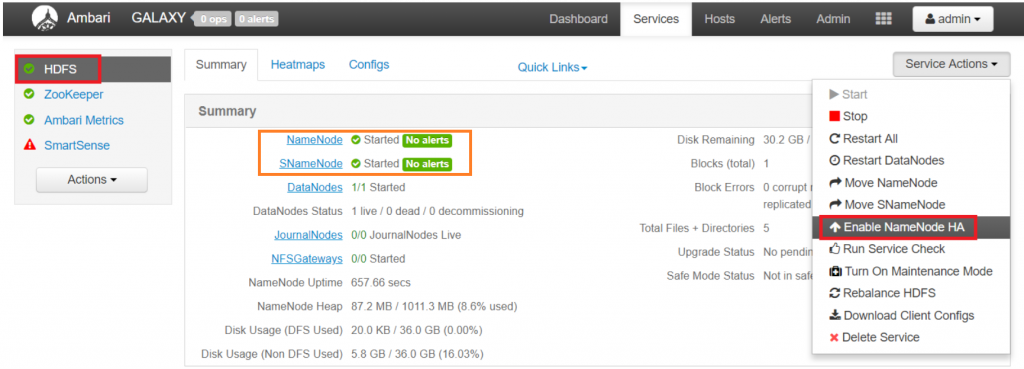
From Ambari UI, select HDFS service
- Review the status of Namenode and Secondary Namenode
- Select “Service Action” download list
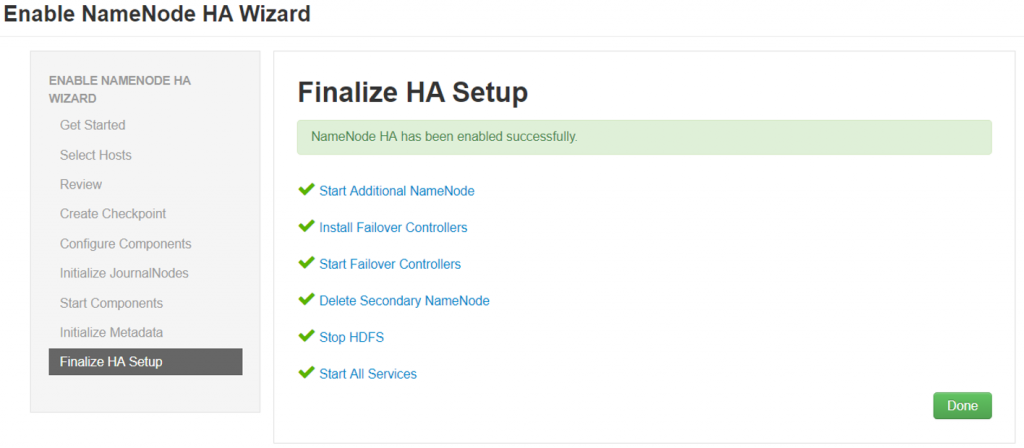
- Select “Enable Namenode HA“
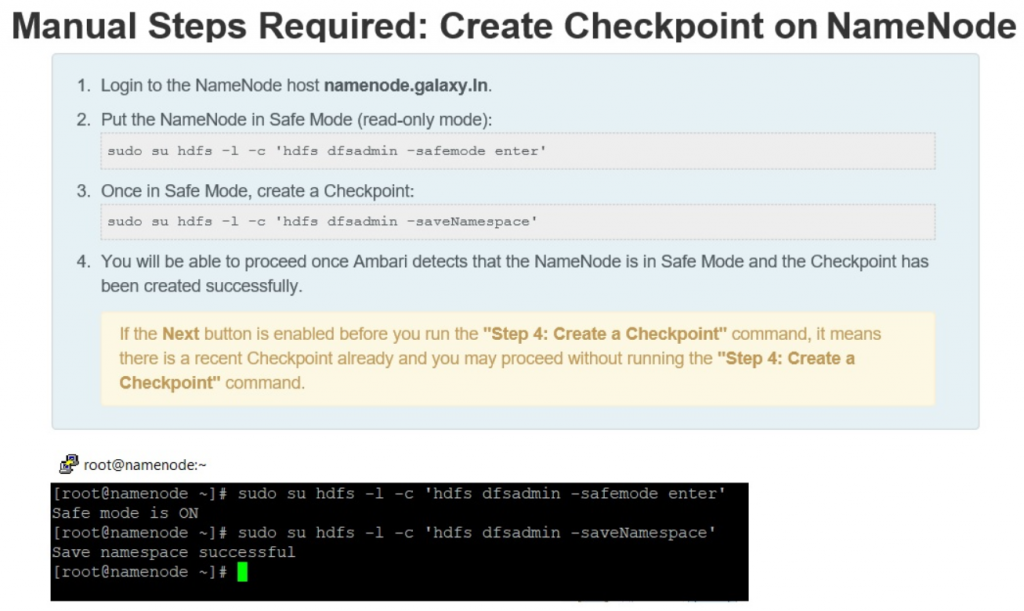
- Create Checkpoint on the Namenode
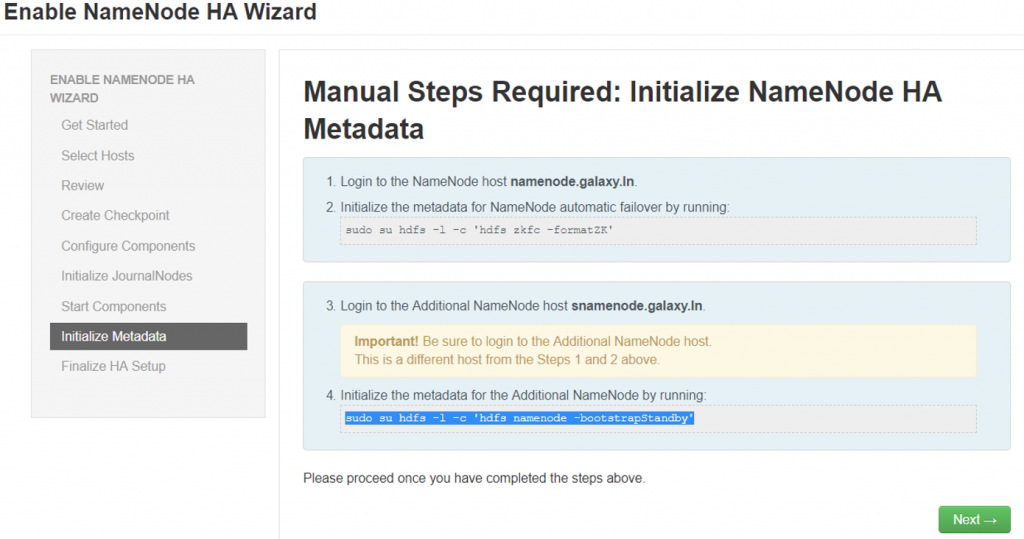
- Login to the Namenode host
- Put the Namenode in Safe-Mode (Read-Only Mode) by typing the below statement in terminal
- su hdfs -l -c ‘hdfs dfsadmin -safemode enter’
- Once in Safe-Mode, create Checkpoint by running the below command
- su hdfs -l -c ‘hdfs dfsadmin -saveNamespace’
- Proceed once Ambari detects that the Namenode is in Safe-Mode & checkpoint has been created successfully
- If the next step/button is enabled before “Create a checkpoint” command, it means there is a recent checkpoint already done, therefore this steps is skipped.
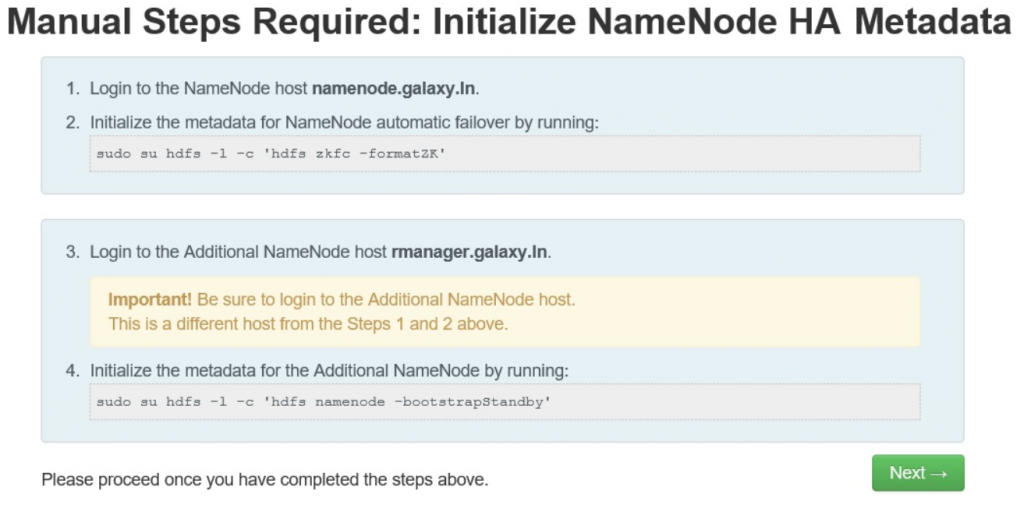
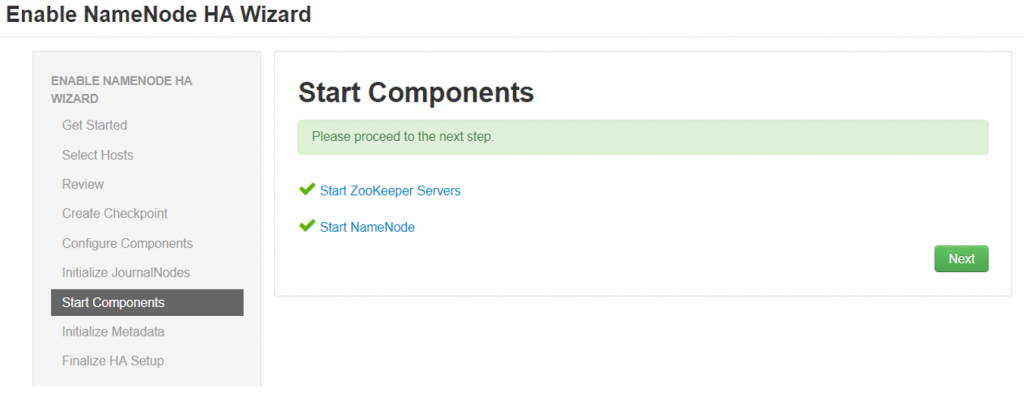
- Run Initialize JournalNodes
- Login to the Namnode host
- Run initialize the JournalNodes command
- su hdfs -l -c ‘hdfs namenode -initializeSharedEdits’
- Ambari will check if the JournalNodes have been initialized successfully

KNOWN ISSUE
When running the ” initializeSharedEdits” command in the above step, if it fails with “No active NameNode was found after 5 retries. Will return current NameNode HA states” message, start Zookeeper services if not running with the below command
su – zookeeper -c “export ZOOCFGDIR=/usr/hdp/current/zookeeper-server/conf ; export ZOOCFG=zoo.cfg; source /usr/hdp/current/zookeeper-server/conf/zookeeper-env.sh ; /usr/hdp/current/zookeeper-server/bin/zkServer.sh start”
I have setup a two nodes lucidworks solr cluster and using zookeeper which comes with HDP. I am configuring solr to store indexes on HDFS. But when my primary namenode goes down and switch over takes place.The solr starts giving error as it doesnt switch over by itself to the new active name node.
when you are using NameNode (NN) HA (High Availability) is there any reason that you are giving the individual hostname of the NN instead of specifying the NameSpace which can be found from fs.defaultFS from core-site.xml
Great content! Super high-quality! Keep it up! 🙂