
OVERVIEW
What is Hadoop?
Hadoop is an open source software framework under Apache project that is used for scalable distributed computing. Hadoop frameworks allows for distributed data processing & storage of large dataset running across a cluster of nodes. Advantage of Hadoop over other high performance computing frameworks is data locality. That is data & computation power resides in the same node as compared to a centralized data storage.
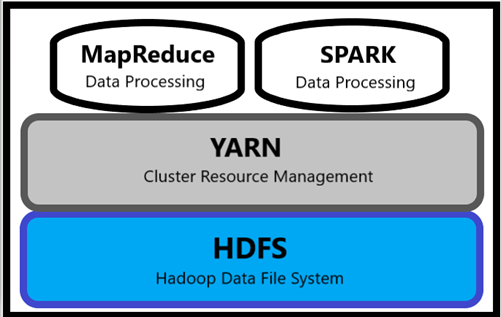
The three main core components of Hadoop are
- Data Processing Engine : MapReduce & Spark are the two main processing engines for data crunching
- Resource Management : Yet Another Resource Negotiator (YARN) provides centralized resource management & governance across Hadoop components
- File System : Hadoop’s primary file system is Hadoop Distributed File System (HDFS) which uses Master/Slave architecture. It is a logical abstraction layer
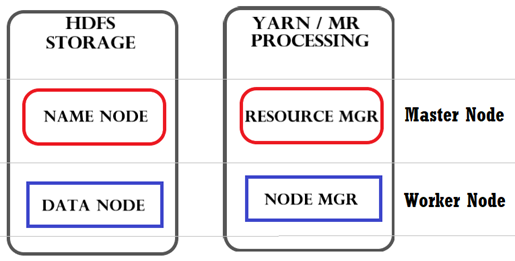
The four main Hadoop daemons are
- Name Node : Stores cluster configuration metadata & runs on Master Node
- Data Node : Stores client data & performs read/write operation. It runs on Worker Nodes
- Resource Manager : Responsible for managing resources across the cluster, it runs on Master Node
- Node Manager : Responsible for managing resources in individual Worker Node
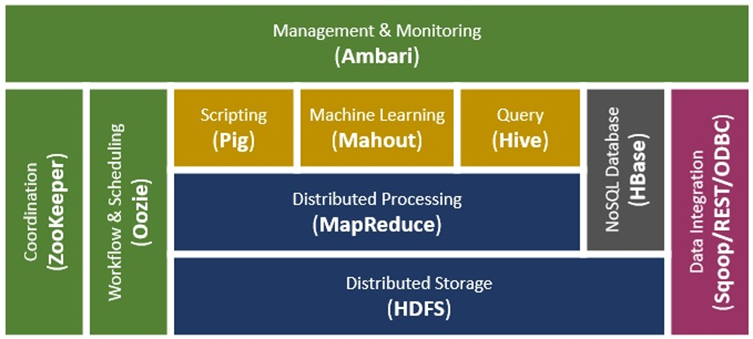
Hadoop Ecosystems
- Core Services: Data processes such as MapRedce, HDFS, YARN & Libraries
- Management Service: Management & monitoring such as Ambari, Oozie, Zookeeper
- Data Access Service: Data access & transformation such as Pig, Hive & Spark
- Data Ingestion Service: Heterogeneous data load such as Flume, Sqoop & Kafka

The content of this Hadoop implementation is based on Hortonworks Hadoop Data Platform (HDP) Ecosystem. This is 100% open source software that can be downloaded from the vendor site. In subsequent sessions the following topics will be covered