Hive is an Apache project software for data warehouse and as part of Hadoop ecosystem it provides data query & analysis interface using SQL like query language know as Hive Query Language (HQL). Hive data processing works on Map Reduce framework making it ideal for processing large data set.
Data files are stored directly on the HDFS under warehouse directory. Hive’s metadata is stored in Hive Metastore, it stores Hive table schema, location, partition and other related information.
Select Add Service from Ambari UI
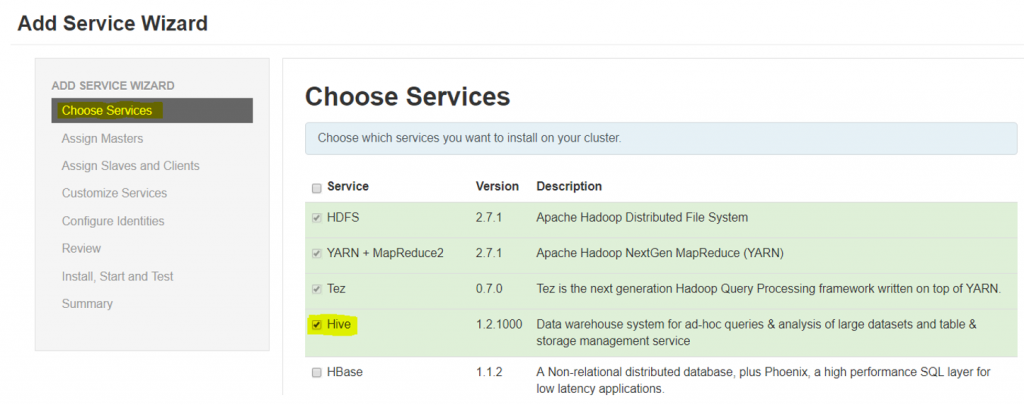
Assign services to cluster nodes
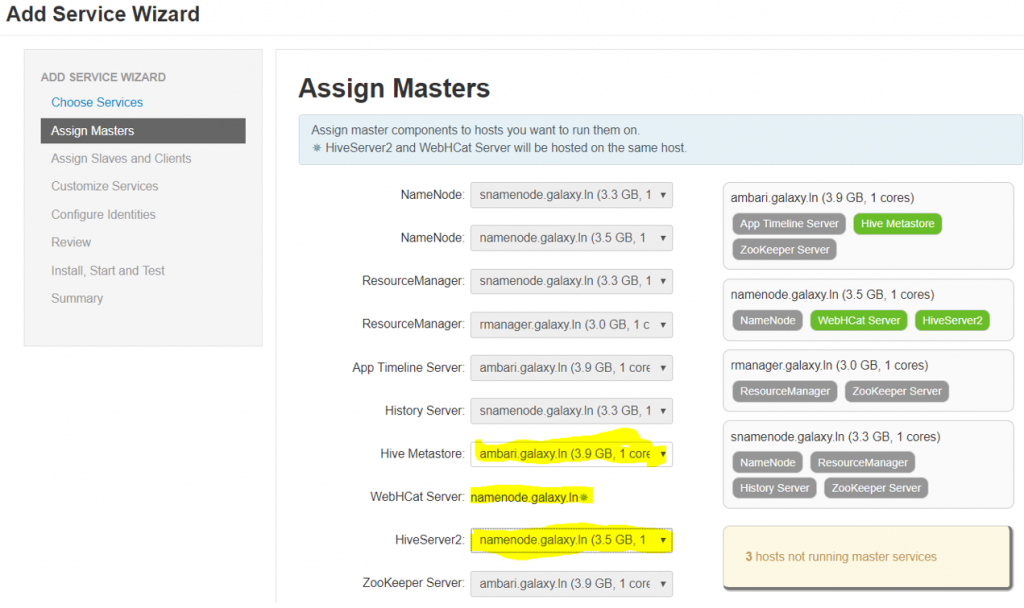
Assign slave and client nodes
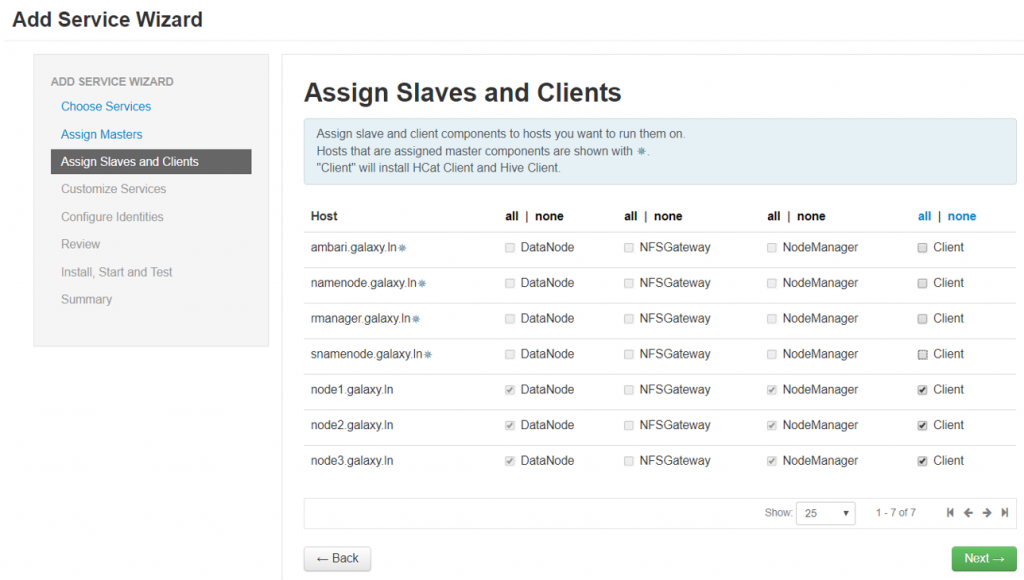
Configure Hive service
Prior to configuring Hive, a Hive database need to be created and appropriate permission granted to root user. In this example mySQL database is used as a repository, therefore login to mySQL, create Hive database and assign the below permissions.

- In Hive tab, select “Advanced” tab
- Select “Existing MySQL/MariaDB Database” option
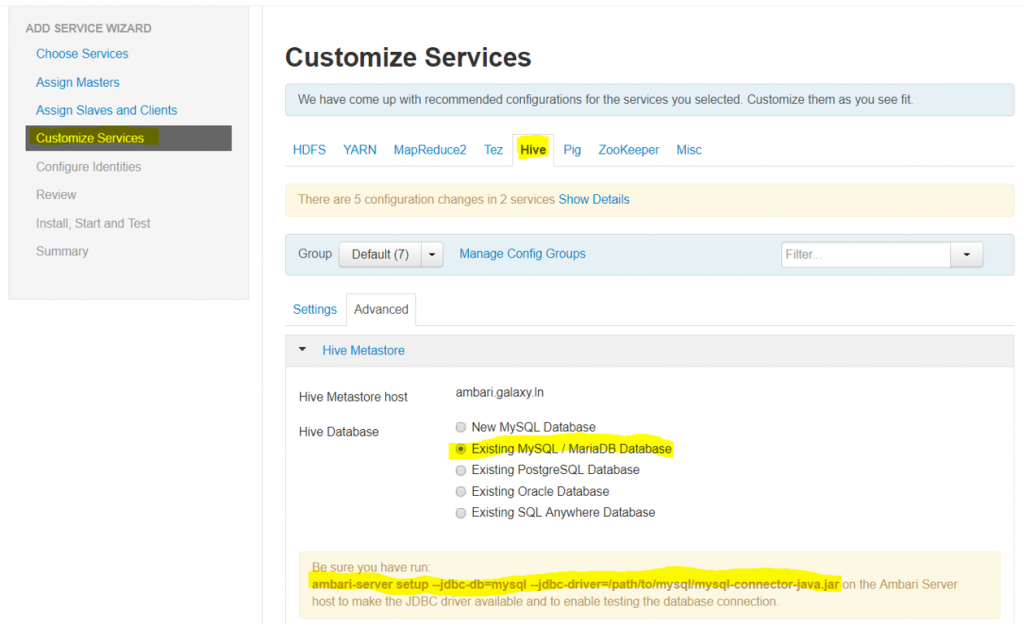
- Run the below command, make sure the jar file path is correct ambari-server setup –jdbc-db-mysql –jdbc-driver=/usr/share/java/mysql-connector-java.jar

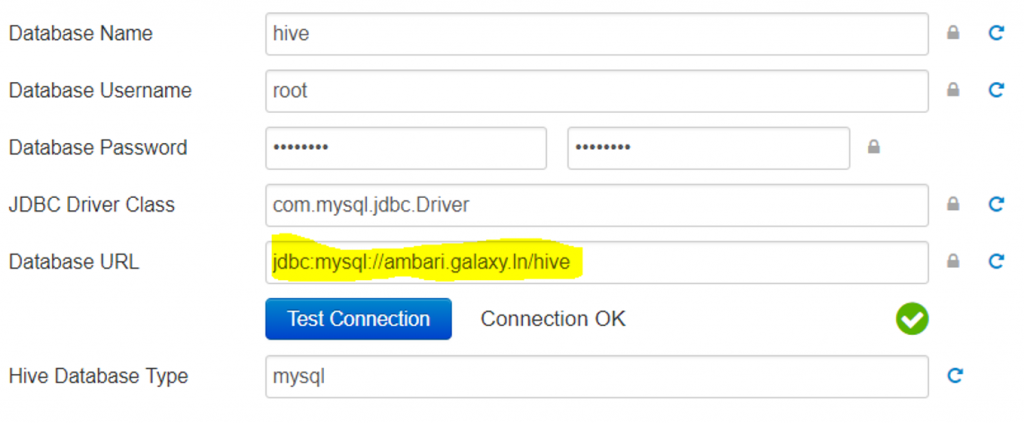
- Populate the database parameters as per screenshot
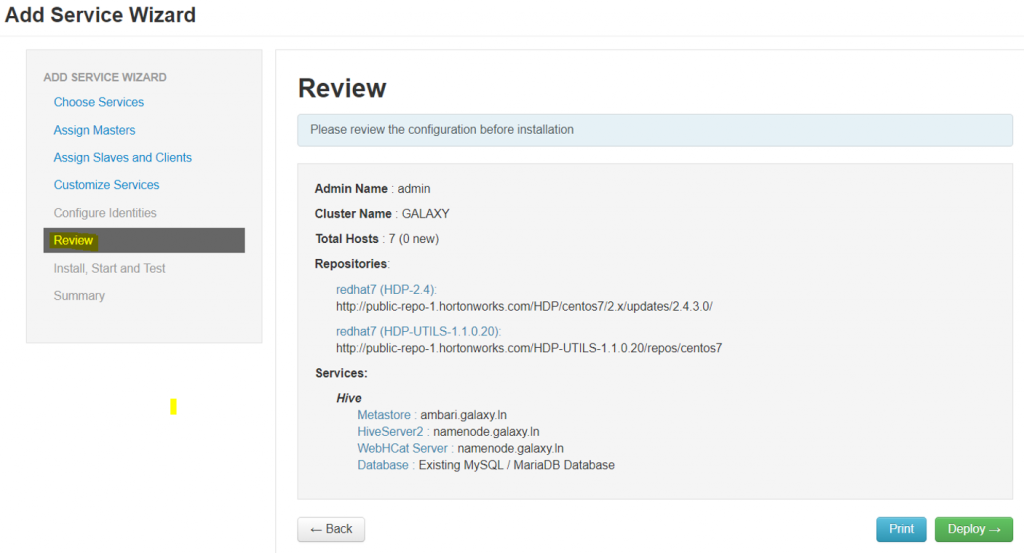
Review and deploy the Hive service
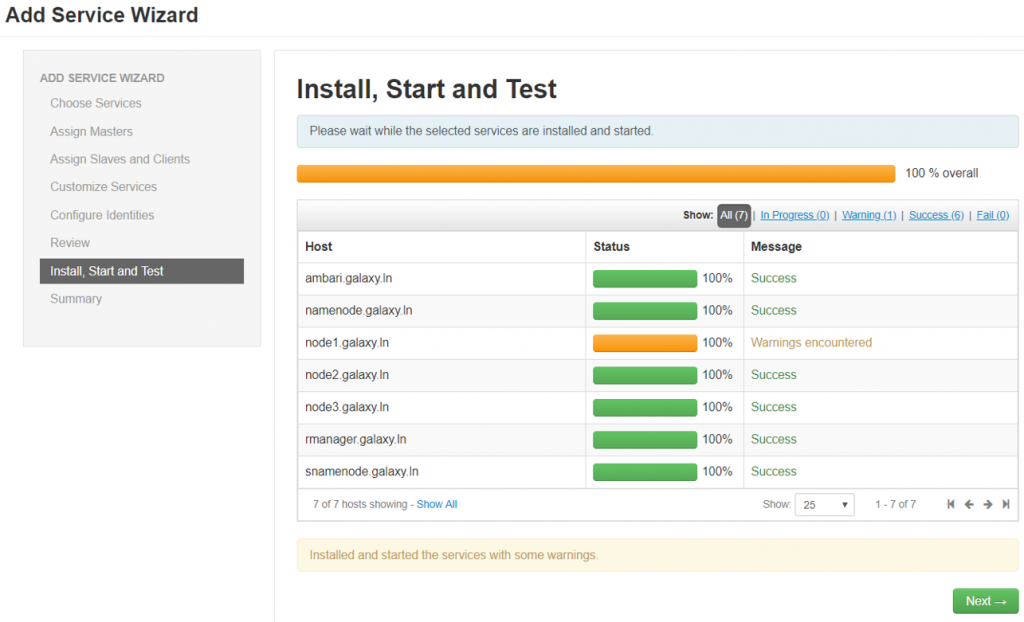
Install service components
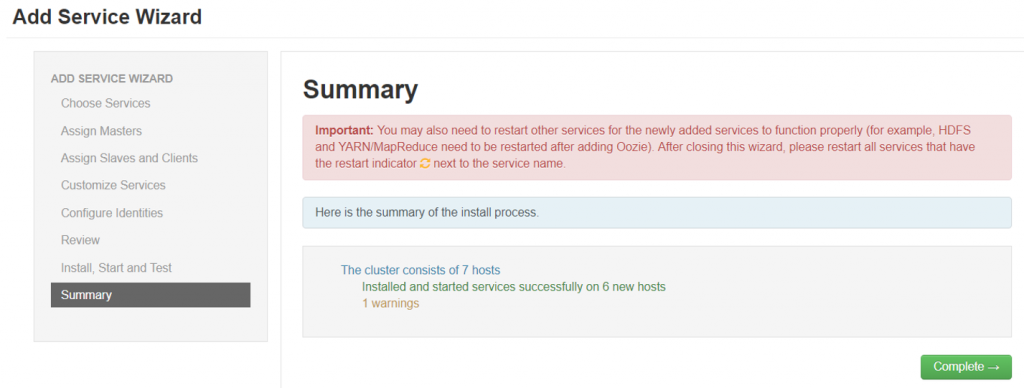
Review deployment summary
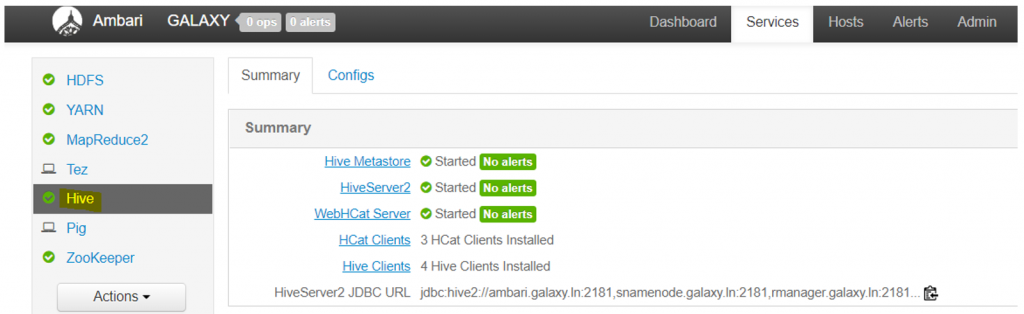
Log into Ambari UI and review Hive service
Follow the above steps to install services such as Spark, Pig, HBase, Ranger, Knox, Tez, Oozie and others.